
Innhold
Sammen med sin nye Mali-G77-grafikkprosessor og Mali-D77-skjermprosessor, har Arm avduket sin siste høyytelses CPU-design - Cortex-A77. Som med fjorårets Cortex-A76, er Cortex-A77 designet for førsteklasses applikasjoner som krever Arms signatur med lavt strømforbruk. Alt fra smarttelefoner til bærbare datamaskiner og ganske sannsynlig utover.
Med Cortex-A77 har Arm målrettet mot maksimal instruksjon per syklus / klokke (IPC) ytelsesøkning den kan klare over Cortex-A76. Klokkefrekvenser, strømforbruk og område er alle designet for å forbli omtrent i den samme ballparken, men den nye kjernen kan knaske gjennom mer instruksjon på en gang. For å gjøre dette har Arm designet en enda bredere kjerne enn i fjor og har gjort en rekke forbedringer for å holde CPU-kjernen matet av ting å gjøre. Men før vi kommer til det, la oss dykke ned i høynivåoversikten og ytelsesnumrene.
Treffer ytelsesmål
Tilbake i august 2018 delte Arm ukarakteristisk et CPU-veikart frem til 2020. Fra 2016s Cortex-A73 til 2020s “Hercules” -design, lover selskapet en 2,5x økning i beregningsytelse. En god del av denne enorme projeksjonen ble oppnådd med det store mikroarkitekturskiftet med Cortex-A76, høyere moderne klokkehastigheter, og flyttingen fra 16 til 10 og nå 7nm produksjon med 5nm å følge. Omtrent 1,8x av gevinstenes rutekart ble allerede oppnådd i fjor, og Cortex-A77 gir en cirka 20 prosent ytterligere IPC-boost. Dette setter oss godt på vei til Arm's 2,5x mål, selv om mobile enheter med begrenset strøm og termiske budsjetter ikke forventer å se alle disse gevinstene.
Til sammenligning ga fjorårets Cortex-A76 rundt 30-35 prosent økning i forhold til Cortex-A75. I år ser vi på en mer dempet, men likevel betydelig 20 prosent IPC-gevinst mellom A77 og A76. Dette er gode nyheter fordi det betyr mer ytelse mens du holder deg til lignende termiske og strømbegrensninger som før. Avveiningen er at A77 er omtrent 17 prosent større enn A76, så vil koste litt mer med tanke på silisiumområdet. Hvis du vil ha en sammenligning med desktop-lederne, klarte AMD et 15 prosent IPC-løft mellom Zen2 og Zen +, mens Intels IPC har holdt seg praktisk talt statisk i årevis.Selvfølgelig snakker vi forskjellige markedssegmenter her, men dette viser hvordan Arms CPU-designteam har oppnådd imponerende gevinster de siste generasjonene.
En 20% ytelsesøkning tilbys for neste generasjons Cortex-A77 baserte SoCer
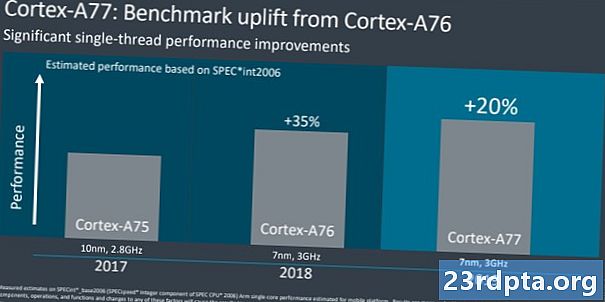
Takeaway her er at A76 markerte et stort mikroarkitektonisk skifte med enorme ytelsesgevinster, mens vi er tilbake til optimeringsnivåforbedringer med A77. Med det ute av veien, la oss dykke inn i det som er nytt i Arm Cortex-A77.
Cortex-A77 bygger på A76 mikroarkitektur
Nøkkelen til å forstå forskjellen mellom Cortex-A77 og A76 er å forstå hva som menes med en "bredere" kjernedesign. I hovedsak snakker vi muligheten til å utføre flere instruksjoner for hver klokkesyklus, noe som øker kjernens gjennomstrømning. Det er to viktige deler for å få dette til - å øke antall utførelsesenheter for å utføre behandlingen og sikre at disse enhetene blir godt matet med data. La oss begynne med den siste delen og fokusere på utsendelses-, cache- og grenprediktordeler av SoC.
Cortex-A77 ser et løft på 50 prosent for å sende bredden, opptil seks instruksjoner per syklus fra fire med A76. Det betyr flere instruksjoner på vei til utførelseskjernen for hver klokkesyklus for større ytelsespotensial. Utførelsesvinduet som ikke er bestilt, er også større som et resultat, og øker til 160 oppføringer for å avsløre mer parallellitet. Det er en kjent 64K instruksjonsbuffer, mens Branch Target Buffer (BTB), som har adresser for grenprediktoren, er 33 prosent større enn før for å håndtere veksten i parallelle instruksjoner. Ikke noe uvanlig her, det er egentlig en bredere versjon av fjorårets design.
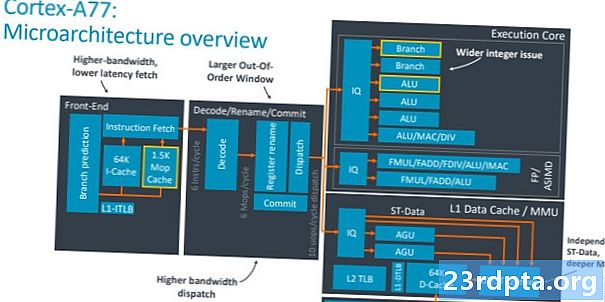
Det mer spennende fronttilskuddet er den helt nye 1.5K MOP-hurtigbufferen, som lagrer makro-Ops (MOP) som mates tilbake fra dekodeenheten. Arm's CPU-arkitektur avkoder instruksjoner fra en brukers applikasjon til mindre makrooperasjoner og deretter videre ned i mikro-ops som utførelseskjernen forstår. Du kan se dette på diagrammet ovenfor i avkodingsseksjonen. MOP-cachen brukes til å redusere kostnadsstraffen for tapte grener og flushes, når du holder tak i makro-opsjoner i stedet for å dekode dem igjen, og øker kjernens totale gjennomstrømning. Henter fra MOP i stedet for i-cache utenom dekodetrinnet, og sparer en syklus. Arm uttaler at MOP-cachen kan treffe 85 prosent eller mer treffprosent på tvers av en rekke arbeidsmengder, noe som gjør det til et veldig nyttig tillegg til standard i-cache.
Når du beveger deg ned til kjøredelen av prosessoren, må du legge til en fjerde ALU- og andre filialenhet. Denne fjerde ALU øker prosessorens generelle antall knusing av båndbredde med 50 prosent. Denne ekstra ALU-en er i stand til grunnleggende en-syklus-instruksjoner (for eksempel ADD og SUB) pluss to-syklusers heltalloperasjoner, slik en multiplikasjon. To av de andre ALU-ene kan bare håndtere grunnleggende en-syklus-instruksjoner, mens den endelige enheten er ladet med mer avanserte matematikkoperasjoner som divisjon, multipliserer akkumulering, etc. Den andre grenenheten inne i utførelseskjernen dobler antallet samtidige grenhopp core kan håndtere, noe som er nyttig i tilfeller der to av de seks avsendte instruksjonene er grenhopp. Dette høres litt rart ut, men intern testing hos Arm avslørte ytelsesfordeler ved å ta i bruk denne andre enheten.
Cortex-A77 tilbyr forbedret parallellitet og en ny bruk av forhåndshentede buffer
Andre justeringer til CPU-kjernen inkluderer tillegg av en andre AES-krypteringsrørledning. Rørledningene i datalageret har nå dedikerte utgaveporter for å doble minnebåndbredden. Disse portene ble tidligere delt med ALU-ene, som noen ganger kan bli en flaskehals. Det er også en neste generasjons data perfecter for å forbedre effektiviteten og samtidig øke båndbredden til system DRAM.
En del av dette systemet i Cortex-A77 har også et helt nytt "system-bevisst" prefetch-system. Dette forbedrer minneytelsen basert på et bredt spekter av CPU-kjernetellinger, hurtigbufferkapasitet og latenstid og hukommelsessystemsystemkonfigurasjoner i endelige enheter. Den dedikerte maskinvaren for å snakke med Dynamic Scheduling Unit (DSU) som en del av en DynamIQ CPU-klynge, som overvåker bruken av den delte L3-cachen. Kjernen har dynamiske avstands- og aggressivitetsnivåer for å redusere cacheutnyttelsen i situasjoner der L3-båndbredde er begrenset av andre CPU-kjerner. Kjerner med høyere ytelse som Cortex-A77 er mer sannsynlig å mette DSU-tilgang til minne, mens kjernene med lavere effekt som A55 neppe vil.

Passer alt sammen
Det er mange små endringer i Cortex-A77 som gir noen betydelige forskjeller til forgjengeren. I et nøtteskall hjelper A77s nye MOP-cache kombinert med et bredere og lengre instruksjonsvindu med å holde ALU-, Branch- og minneenhetene opptatt med ting å gjøre. Kraftverket Cortex-A76-designet er utvidet for å forbedre gjennomstrømningen ytterligere med A77, uten å stole på høyere klokkehastigheter.
Den største ytelsen øker til at Cortex-A77 ankommer i form av et heltall og flytende punktmatematikk. Dette bekreftes av Arms interne benchmarks, som viser en ytelsesøkning på 20 til 35 prosent i henholdsvis SPEC-heltal og flytende punkt-benchmarks. Forbedringer i minnebåndbredden sitter et sted mellom 15 og 20 prosent, og fremhever igjen at de største gevinstene kommer i form av tallknusing. Totalt sett gir disse forbedringene A77 gjennomsnittlig 20 prosent oppgang i forhold til forrige generasjon. Vi kan også se noen ytterligere, mer marginale gevinster som et resultat av mer avanserte 7nm produksjonsprosesser senere i år eller tidlig i 2020.
Når det gjelder smarttelefoner, er Cortex-A77-drevne SoC-er beregnet på flaggskipprodukter med høy ytelse. Arm forventer fullt ut å se drivhusdesign bruke 4 + 4 bit. LITTE kjernearrangementer. Gitt den økte gjennomstrømningen og svake humlegraden til arealstørrelsen på A77, vil vi sannsynligvis se SoC-designere fortsette nedover 1 + 3 + 4 eller 2 + 2 + 4-trenden. Med en eller to kraftige store kjerner med større cacher og høyere klokker, sikkerhetskopiert av 2 eller 3 A77-kjerner med mindre cache-størrelse og lavere klokker for å spare strøm og areal. Til slutt stave Cortex-A77 gode ting for smarttelefonchips og det voksende markedet for alltid tilkoblede armbaserte bærbare datamaskiner. Hold øye med silisium kunngjøringer senere i år.


